![]()
|
|
|
|
I 5. Data Integration: Context, Meme Complexes and Tasking Intent
1. Posted: November 15, 2003
Remote Viewing Proposals Data Integration in RV: Abstraction Levels and Context
Problem: While most remote viewing sessions appear to demonstrate some degree of target contact, integrating the data into the correct context is perhaps the greatest challenge a viewer has to face. Even assuming that noise is minimized, that most of the sensory elements are representative of the actual target, how does one actually decide on a particular scenario, a way of connecting them? Which are the central aspects of the target, worth probing through advanced techniques, and which - mere peripherals? Often the breakthrough comes naturally, as a CRV Stage 3 or Stage 4 "impact": one gets a sudden feeling for the overall impression of the site ("research installation", "war zone", "street scene", etc). The bulk of the data seems to fall into place, to coalesce into an overall impression that is virtually impossible to ignore for the rest of the session - with advanced protocols functioning to collect more detail about specific aspects, but rarely able to reverse the overall nature of this spontaneous conclusion. What if, however, this overall impact is not forthcoming? What if the data is too disparate, forming two or more possible conceptual basins? How can we identify the target's "center of gravity" and circumscribe the relevant basin of associations? Another very common problem is that of "doorknobbing": in his 2003 book The Seventh Sense, Lyn Buchanan has described this as the tendency of a viewer to become "so attracted to one part of the site that he/she accepts that part as the designated target and completely misses the assignment. In this situation, the viewer literally can't see the forest for the tree" (pp. 227). The main issue we'd like to address is therefore this: how can we identify the fulcrum point of the session, the central gestalt which forms the tasker's primary interest - in the absence of a monitor and any other front loading questions? Example: "Elvis Presley, Friedberg Germany 1960" - HRVG target HSDE-HHWL.
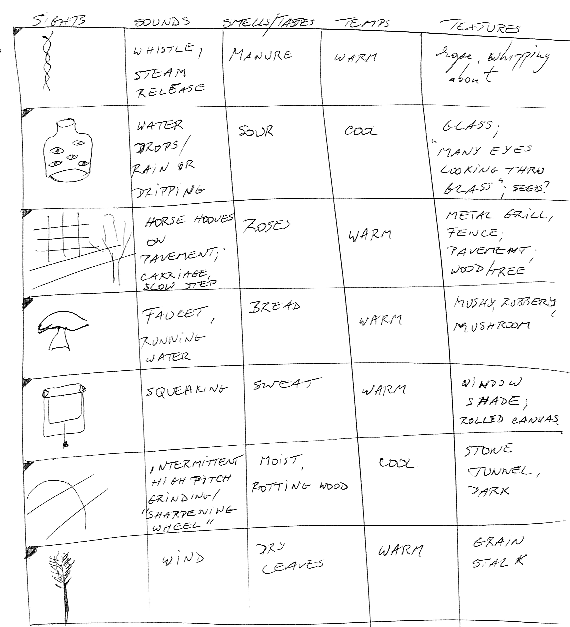
This target picture shows something rather non-specific from a "tangible detail" point of view: a young male with black hair, wearing a military uniform and sitting in front of a wall map, laughing. The more interesting and specific details, in this target, would fall under "intangibles", or abstract data: it would be nice to realize that this man was Elvis; that the setting had something to do with military operations - yet a war was not necessarily involved; the time and place would be nice - and also anything else that was likely to be on his mind around that time - perhaps publicity, his career, his daily duties etc. But most of our internal dialogue with the subconscious, at least at the S1-S2 stage, consists of cueing for tangibles. So the subconscious was happy to oblige, going where it could find them (see collection matrices below). Playfair
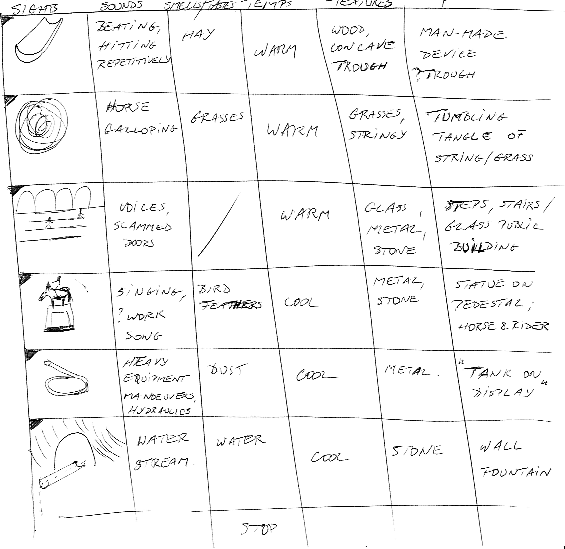
S2 Collection Matrix
Note that two major association basins immediately emerge:
and "rope, whipping about - grain stalk - trough - tumbling tangle of string/ grass - horse hooves on pavement, carriage, slow step - high-pitch grinding, "sharpening wheel" - horse galloping - wind - dry leaves - moist rotting wood - bread - manure - hay - grasses - bird feathers" - all rural imagery which would reasonably fit with the type of landscape present around Friedberg. Somewhere at the end of S2 I had two interesting rows: the image of a tank and that of a man on a horse (metal and stone statue); sounds: "singing, work song - and "heavy equipment manoeuvres, hydraulics"; P: "statue on pedestal - horse and rider" - and "tank on display". Interestingly enough, in the S2 Phonics stage, the words "barrack", "catapult" and "press" were recorded - but once again, the preponderant imagery was farm-related. How did I make sense of this data in S3? Since most of my tangibles screamed "agricultural setting", I turned the tank into a "combine" (I actually had to dig deep into my memory to find some kind of agricultural implement that would look like a tank!) and the man on a horse into a horse-pulled cart hauling hay. Not only that - the sense of war artifacts somehow out of place/use was so strong, and clashed so badly with all the rural imagery, that I had a note in my Cascade: "Another possibility - this is part of a museum exhibit and refers to old South, cotton gin, civil war artifacts". After the feedback became available, a quick Web search for collateral information revealed that Elvis was enrolled in the 3rd armored division during his army duty ('58-'60) and "could drive, load and shoot an M-48 Patton Battle Tank" (Also in the musical film they shot there in 1960, "GI Blues", he plays a tank operator).
Discussion: This rather dismal failure to properly integrate the low-level data, even when highly specific and pertinent details are clearly fed by the subconscious, is perhaps something typical of inexperienced remote viewers - something that becomes less and less problematic after several years of practice. Yet even if that were true, the fundamental process which leads to it is something that we need to consider in situations where a viewer is faced with a target of a highly abstract, novel nature: the tendency to focus on tangible information and to allow the "majority" of mutually consistent details to coalesce, or self-assemble, into an attractor that becomes, de facto, the central gestalt, is something so natural to our conscious orientation instincts that it may typically lead to the wrong conclusions when faced with an abstract concept, such as a scientific target. The reason is that highly abstract concepts are by definition "statements about statements" or, to use a genetic analogy, multiple-base codons translating into a particular conceptual "amino-acid" (also see Pitkanen's "Genes and Memes" in this issue for a possible physical model of this RV interface): their representation in our brain consists not of mental images, but of entire association basins - simple sensory and emotional mental images strung together by other basic representations, such as movement, transformation, spatial relationships, etc. The more we activate a given association network, the more this pattern is evoked in connection with the proper, conscious abstract term denoting it, the easier it becomes to recognize that concept. Also, as we all know, the activation of only one or two images which are part of this basin is more likely to stimulate the entire network once these synapses have been sufficiently strengthened. The duration of the typical, early target contact in RV has not been quantified, but as everyone familiar with the process knows, it is extremely brief, sufficient to capture only one fleeting sensory or conceptual image at a time. What this means is that the only way for the subconscious to communicate abstract information about the target is via a sequence of "active vocabulary" imagery and/or metaphors (also see Buchanan 2003, p 254 for basic vocabulary exercises) The early stages (S1-S2 in the HRVG methodology) yield a very broad distribution of such low-level data points... One could imagine them spread over the surface of a sphere, which is one's global mental map: these points of data begin to gravitate toward one another based on mutual consistency, and "clump" together into subconscious or semi-conscious proto-scenarios; as the pieces of the puzzle begin to fall into place they create a sense of internal space - the memory of which may be part of the reason for which one's later data seems so much more cohesive. The problem is therefore that by the time one reaches S3 the overall meaning, or center of gravity of the target, seems to be determined merely on the basis of this "self-assembly" of corroborating low-level details: as in Consensus Analysis, solitary or incongruent details will be given less attention than those which fall easily within the emergent framework. But what if most of these tangible, recognizable, mutually-consistent details are peripheral to the target, as was the case in the above example? Alternatively, what if they are each part of a metaphorical/abstract complex the subconscious is trying to construct? Is there a possibility that the strong emphasis on purely tangible data in the early stages of the session, and the mere abundance of convergent, sensory details could lead a viewer off-track at least for certain types of targets? And if so, how can we offset this bias? How do we determine the proper level of abstraction on which we ought to integrate the data, and the target's intended center of gravity?
1. Functional Cueing
Proposal: What I would like to argue is that while the tangible details are ultimately the types of things the tasker will find most valuable, the road to a MEANINGFUL set of tangibles is best chosen if first passing through the right basin of abstraction. But how can we circumscribe it? There have been many interesting approaches to this problem, even though the question they sought to address may not have been formulated quite this way. One of Lyn Buchanan's very interesting suggestions, for example, is that his students practice so called "ambiance exercises", trying to detect the difference between every space they enter and the one they just left: this is supposed to increase the student's sensitivity to subtle changes in his/her perceptions - but, we believe, it may also function to help recognize specific mental contexts and distributions of impressions which would not otherwise receive a conscious name ( see The Seventh Sense, p 251). Bill Stroud, one of Lyn Buchanan's advanced students, has devised another ingenious approach (see Stroud articles in this issue): assuming that every instance of analytic overlay, or STRAY CAT, contains some relevant information about the target, he has decided to filter his sessions through an Essential Overlay Matrix, in which each image is decomposed into its major structural and functional associations; by comparing these connotations, the viewer is then able to identify the common denominator and make a decision about which aspects of his data are probably relevant to the target. Both of these ideas are highly innovative and probably something to be incorporated into every viewer's navigational tool. What we would like to propose, in this article, is something far less sophisticated, but hopefully equally useful: the application of a few general, conceptual cues relatively early in the RV session, in order to counter-balance the self-aggregation of tangible data into premature scenarios and also to circumscribe the abstraction level toward which the viewer ought to aim his/her integration. To grasp the overall nature of the target (which incorporates the tasker's specific intent or focus), one could try to perform a "contextual sweep" along a number of abstract dimensions, as follows. "Are any of the following cues relevant to this target (tasker intent) and if so, characterize": - type of energy predominant at the target (i.e. static, heat, light, living,
mass, motion, electricity etc?) These general categories provide non-contiguous perspectives on the target and are abstract enough that, we believe, they pose relatively little risk of triggering an analytic overlay drive. The "characterization" should be open-ended, rather than forced-choice, but we suggest that the viewer practice in order to become proficient with describing locations, events, etc in terms of such general aspects - much like Buchanan's Ambience Exercises. Used right after the initial set of ideograms (HRVG S1), before the accumulation of tangible data, these cues could provide an uncontaminated, unbiased "scaffolding" of functional information to be set aside until the viewer is ready to make an initial, deliberate attempt at integration: at that point, the viewer can use these axes to guide his/her integration process, identify strengths and weaknesses in the type of data obtained, and decide which aspects to expend more time on in the advanced protocols. A similar cueing process could be applied at that advanced stage, such as: 1. what is the general sphere of activity in which humans typically interact with the target (i.e. sustenance, transportation, scientific enquiry, art, defense etc) 2. typical emotions the target evokes in people 3. what is the form in which the greatest amount of energy or mental focus is spent at the target (i.e. growth and transformation of living/inert structures; production of energy/ force; representational process such as art, mathematics; movement, transportation; learning/understanding; classification/organization; distribution/spread or gathering/attraction; repair (healing, reconstruction) - etc etc These are of course only suggestions - we propose that viewers' own analysis identify where data integration took a wrong turn for each session and what type of general information would have been beneficial at that point - such that a general pool of situation-specific cues may be designed and used for future navigation. What are the risks of such an approach? Clearly, if the cueing triggers a highly specific answer, the likelihood of AOL drive from this point on is considerable. For this reason, during the collection of S1-S2 data, the information elicited through these exercises should not be given any more consideration than every other piece of matrix data: ideally each should be recorded, then erased from the viewer's short-term memory and the target should be probed as if for the first time. Otherwise, trying to establish the general context too early in the process might unduly restrict or contaminate the data with preconceived notions. One's ability to temporarily disregard the results of these early contextual cues needs to be weighed against the ability to fight a premature scenario based on the aggregation of tangible S1-S2 information: both are a matter of psychology, rather than intrinsic process. But are there valid, process-based objections to this exercise? Is there a reason to believe that target aspects such as energy, function or emotions CAN NOT typically and reliably emerge so early in the process? This is perhaps an answer that can only be given by controlled experimentation and comparing the scores of standard sessions with those in which this cueing is used.
2. Creating artificial, abstract vocabularies
Proposal: To look into the possibility of creating an artificial ideogram/mental image vocabulary of highly abstract terms, with application to specific sciences/disciplines. This suggestion has to do with the abstract vocabulary we mentioned earlier in this article: for elements of the target that are recognizable, sensory mental images, the translation process is rather easy... But the more abstract the concept is - the more images it takes to construct the context, and the harder it becomes to identify the "right codon". Every time one re-sweeps the target, there is a good chance the perspective has changed, or one is no longer on the same aspect of the target. So the viewer ends up with a few dozen sensory and simple conceptual bits of data, begging the question: is there a novel, higher-level meaning that is supposed to emerge from all this, or is one supposed to take the data in a relatively literal sense? I think this becomes quite an important distinction in science applications, and anywhere else we have to balance known concepts against novel, unknown ones. Joe McMoneagle might have referred to the same problem when he talked about the difficulty of making predictions that are far into the future (The Ultimate Time Machine), given that we simply can't expect to understand technology which is so far advanced. But I think the same applies in everyday situations where a viewer is pitched against relatively unfamiliar concepts. Simple example: the viewer gets "grid; cross; cluster of points; snake-like curve". Most individuals seem conditioned to look for a pattern which fits this cluster of data on a tangible level - so they might come up with something like a group of people walking along a set of intersecting alleys at a zoo, watching a snake in a cage; however, to a mathematician trained to think primarily in abstract terms, the same cluster of data might immediately suggest the action of plotting a set of experimental results on a coordinate grid and tracing the best-fit function - while the actual shape of the "snake-like" curve might provide meaningful information about the type of function describing this situation. Since the level on which we tend to naturally integrate the data seems to be dependent on our own background, would it be possible to artificially design cues meant to identify the proper abstraction level required for a given target? And could we reduce the likelihood of "translation error" by artificially building a vocabulary of abstract concepts - to be trained into the mind as "single mental images", replacing the natural shortcut loops which form with extensive exposure to a particular field? We might be able to test the effectiveness of this exercise by training a group of viewers in such a vocabulary, then tasking both that group and a control group with the same set of specialized targets, and using separate, blind analysts to derive the meaning of the target. For the procedure to be successful, the first group would have to produce accurate, significantly higher-score reports about the precise conceptual meaning of the target.
REFERENCES
Buchanan, Lyn (2003) The Seventh Sense. Paraview Pocket Books, New York, NY 2003 Stroud, Bill (2001) Making a Stray Cat Prolific: Thesaural Imaging and Remote Viewing. JNLRMI II(3) November 2003 Stroud, Bill (2001) The Essential Overlap Matrix: An Extension for a Remote Viewing Tool. JNLRMI II(3) November 2003 Pitkanen, M. (2003) Genes and Memes. JNLRMI II(3). November 2003 McMoneagle, Joseph (1998) The Ultimate Time Machine: A Remote Viewer's Perception of Time and Predictions for the New Millennium. Hampton Roads Publishing Co. Charlottesville, VA 1998
2. Posted: November 15, 2003
Meme Complex Recognition and AOL Drive
Problem: Assuming correct integration is achieved prior to the session's end-point (such as S3 in the HRVG method), how dependable is the viewer's data from this point on, considering the basin of associations against which he/she now has to struggle? How can we balance context recognition against "meme complex identification"? Lyn Buchanan has suggested (in FAQs on P>S>I website) that a monitor, in this situation, should keep moving the viewer against unknown aspects of the target (see below) What about unmonitored sessions? Should the viewer focus on general aspects which fit easily in the overall context (but which, for that very reason, could be attributed to the mind "filling in the blanks") or on unusual, idiosyncratic aspects (which might be a significant signature of the target, but might also represent noise having nothing to do with the signal?
Replies / References Posted: November 15, 2003 See "Can The Viewer Ever Identify Things?" by PJ
Gaenir and Lyn Buchanan See The Essential Overlap Matrix: An Extension for a
Remote Viewing Tool Making a Stray Cat Prolific: Thesaural Imaging
and Remote Viewing Cassirer, on the Expressive Form of Mythopoeic
Thought: A Foundation for Buchanan's Concept of Ambiance
|
|
Copyright � 2000-2006 EmergentMind.org
|