![]()
|
|
|
|
Remote Viewing Proposals Data Integration in RV: Abstraction Levels and Context MindLab03 Section References
Problem: While most remote viewing sessions appear to demonstrate some degree of target contact, integrating the data into the correct context is perhaps the greatest challenge a viewer has to face. Even assuming that noise is minimized, that most of the sensory elements are representative of the actual target, how does one actually decide on a particular scenario, a way of connecting them? Which are the central aspects of the target, worth probing through advanced techniques, and which - mere peripherals? Often the breakthrough comes naturally, as a CRV Stage 3 or Stage 4 "impact": one gets a sudden feeling for the overall impression of the site ("research installation", "war zone", "street scene", etc). The bulk of the data seems to fall into place, to coalesce into an overall impression that is virtually impossible to ignore for the rest of the session - with advanced protocols functioning to collect more detail about specific aspects, but rarely able to reverse the overall nature of this spontaneous conclusion. What if, however, this overall impact is not forthcoming? What if the data is too disparate, forming two or more possible conceptual basins? How can we identify the target's "center of gravity" and circumscribe the relevant basin of associations? Another very common problem is that of "doorknobbing": in his 2003 book The Seventh Sense, Lyn Buchanan has described this as the tendency of a viewer to become "so attracted to one part of the site that he/she accepts that part as the designated target and completely misses the assignment. In this situation, the viewer literally can't see the forest for the tree" (pp. 227). The main issue we'd like to address is therefore this: how can we identify the fulcrum point of the session, the central gestalt which forms the tasker's primary interest - in the absence of a monitor and any other front loading questions? Example: "Elvis Presley, Friedberg Germany 1960" - HRVG target HSDE-HHWL.
This target picture shows something rather non-specific from a "tangible detail" point of view: a young male with black hair, wearing a military uniform and sitting in front of a wall map, laughing. The more interesting and specific details, in this target, would fall under "intangibles", or abstract data: it would be nice to realize that this man was Elvis; that the setting had something to do with military operations - yet a war was not necessarily involved; the time and place would be nice - and also anything else that was likely to be on his mind around that time - perhaps publicity, his career, his daily duties etc. But most of our internal dialogue with the subconscious, at least at the S1-S2 stage, consists of cueing for tangibles. So the subconscious was happy to oblige, going where it could find them (see collection matrices below). Playfair
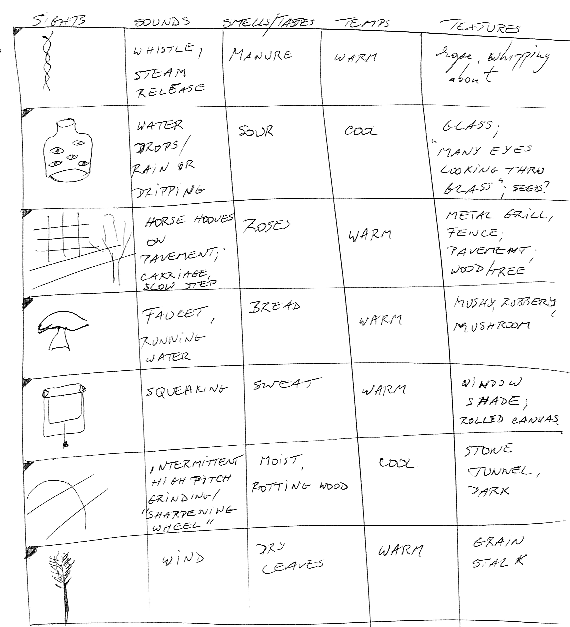
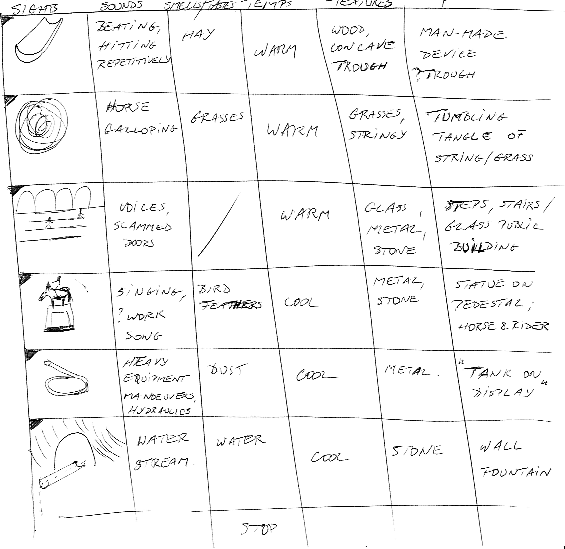
S2 Collection Matrix
Note that two major association basins immediately emerge:
and "rope, whipping about - grain stalk - trough - tumbling tangle of string/ grass - horse hooves on pavement, carriage, slow step - high-pitch grinding, "sharpening wheel" - horse galloping - wind - dry leaves - moist rotting wood - bread - manure - hay - grasses - bird feathers" - all rural imagery which would reasonably fit with the type of landscape present around Friedberg. Somewhere at the end of S2 I had two interesting rows: the image of a tank and that of a man on a horse (metal and stone statue); sounds: "singing, work song - and "heavy equipment manoeuvres, hydraulics"; P: "statue on pedestal - horse and rider" - and "tank on display". Interestingly enough, in the S2 Phonics stage, the words "barrack", "catapult" and "press" were recorded - but once again, the preponderant imagery was farm-related. How did I make sense of this data in S3? Since most of my tangibles screamed "agricultural setting", I turned the tank into a "combine" (I actually had to dig deep into my memory to find some kind of agricultural implement that would look like a tank!) and the man on a horse into a horse-pulled cart hauling hay. Not only that - the sense of war artifacts somehow out of place/use was so strong, and clashed so badly with all the rural imagery, that I had a note in my Cascade: "Another possibility - this is part of a museum exhibit and refers to old South, cotton gin, civil war artifacts". After the feedback became available, a quick Web search for collateral information revealed that Elvis was enrolled in the 3rd armored division during his army duty ('58-'60) and "could drive, load and shoot an M-48 Patton Battle Tank" (Also in the musical film they shot there in 1960, "GI Blues", he plays a tank operator).
Discussion: This rather dismal failure to properly integrate the low-level data, even when highly specific and pertinent details are clearly fed by the subconscious, is perhaps something typical of inexperienced remote viewers - something that becomes less and less problematic after several years of practice. Yet even if that were true, the fundamental process which leads to it is something that we need to consider in situations where a viewer is faced with a target of a highly abstract, novel nature: the tendency to focus on tangible information and to allow the "majority" of mutually consistent details to coalesce, or self-assemble, into an attractor that becomes, de facto, the central gestalt, is something so natural to our conscious orientation instincts that it may typically lead to the wrong conclusions when faced with an abstract concept, such as a scientific target. The reason is that highly abstract concepts are by definition "statements about statements" or, to use a genetic analogy, multiple-base codons translating into a particular conceptual "amino-acid" (also see Pitkanen's "Genes and Memes" in this issue for a possible physical model of this RV interface): their representation in our brain consists not of mental images, but of entire association basins - simple sensory and emotional mental images strung together by other basic representations, such as movement, transformation, spatial relationships, etc. The more we activate a given association network, the more this pattern is evoked in connection with the proper, conscious abstract term denoting it, the easier it becomes to recognize that concept. Also, as we all know, the activation of only one or two images which are part of this basin is more likely to stimulate the entire network once these synapses have been sufficiently strengthened. The duration of the typical, early target contact in RV has not been quantified, but as everyone familiar with the process knows, it is extremely brief, sufficient to capture only one fleeting sensory or conceptual image at a time. What this means is that the only way for the subconscious to communicate abstract information about the target is via a sequence of "active vocabulary" imagery and/or metaphors (also see Buchanan 2003, p 254 for basic vocabulary exercises) The early stages (S1-S2 in the HRVG methodology) yield a very broad distribution of such low-level data points... One could imagine them spread over the surface of a sphere, which is one's global mental map: these points of data begin to gravitate toward one another based on mutual consistency, and "clump" together into subconscious or semi-conscious proto-scenarios; as the pieces of the puzzle begin to fall into place they create a sense of internal space - the memory of which may be part of the reason for which one's later data seems so much more cohesive. The problem is therefore that by the time one reaches S3 the overall meaning, or center of gravity of the target, seems to be determined merely on the basis of this "self-assembly" of corroborating low-level details: as in Consensus Analysis, solitary or incongruent details will be given less attention than those which fall easily within the emergent framework. But what if most of these tangible, recognizable, mutually-consistent details are peripheral to the target, as was the case in the above example? Alternatively, what if they are each part of a metaphorical/abstract complex the subconscious is trying to construct? Is there a possibility that the strong emphasis on purely tangible data in the early stages of the session, and the mere abundance of convergent, sensory details could lead a viewer off-track at least for certain types of targets? And if so, how can we offset this bias? How do we determine the proper level of abstraction on which we ought to integrate the data, and the target's intended center of gravity?
1. Functional Cueing
Proposal: What I would like to argue is that while the tangible details are ultimately the types of things the tasker will find most valuable, the road to a MEANINGFUL set of tangibles is best chosen if first passing through the right basin of abstraction. But how can we circumscribe it? There have been many interesting approaches to this problem, even though the question they sought to address may not have been formulated quite this way. One of Lyn Buchanan's very interesting suggestions, for example, is that his students practice so called "ambiance exercises", trying to detect the difference between every space they enter and the one they just left: this is supposed to increase the student's sensitivity to subtle changes in his/her perceptions - but, we believe, it may also function to help recognize specific mental contexts and distributions of impressions which would not otherwise receive a conscious name ( see The Seventh Sense, p 251). Bill Stroud, one of Lyn Buchanan's advanced students, has devised another ingenious approach (see Stroud articles in this issue): assuming that every instance of analytic overlay, or STRAY CAT, contains some relevant information about the target, he has decided to filter his sessions through an Essential Overlay Matrix, in which each image is decomposed into its major structural and functional associations; by comparing these connotations, the viewer is then able to identify the common denominator and make a decision about which aspects of his data are probably relevant to the target. Both of these ideas are highly innovative and probably something to be incorporated into every viewer's navigational tool. What we would like to propose, in this article, is something far less sophisticated, but hopefully equally useful: the application of a few general, conceptual cues relatively early in the RV session, in order to counter-balance the self-aggregation of tangible data into premature scenarios and also to circumscribe the abstraction level toward which the viewer ought to aim his/her integration. To grasp the overall nature of the target (which incorporates the tasker's specific intent or focus), one could try to perform a "contextual sweep" along a number of abstract dimensions, as follows. "Are any of the following cues relevant to this target (tasker intent) and if so, characterize": - type of energy predominant at the target (i.e. static, heat, light, living,
mass, motion, electricity etc?) These general categories provide non-contiguous perspectives on the target and are abstract enough that, we believe, they pose relatively little risk of triggering an analytic overlay drive. The "characterization" should be open-ended, rather than forced-choice, but we suggest that the viewer practice in order to become proficient with describing locations, events, etc in terms of such general aspects - much like Buchanan's Ambience Exercises. Used right after the initial set of ideograms (HRVG S1), before the accumulation of tangible data, these cues could provide an uncontaminated, unbiased "scaffolding" of functional information to be set aside until the viewer is ready to make an initial, deliberate attempt at integration: at that point, the viewer can use these axes to guide his/her integration process, identify strengths and weaknesses in the type of data obtained, and decide which aspects to expend more time on in the advanced protocols. A similar cueing process could be applied at that advanced stage, such as: 1. what is the general sphere of activity in which humans typically interact with the target (i.e. sustenance, transportation, scientific enquiry, art, defense etc) 2. typical emotions the target evokes in people 3. what is the form in which the greatest amount of energy or mental focus is spent at the target (i.e. growth and transformation of living/inert structures; production of energy/ force; representational process such as art, mathematics; movement, transportation; learning/understanding; classification/organization; distribution/spread or gathering/attraction; repair (healing, reconstruction) - etc etc These are of course only suggestions - we propose that viewers' own analysis identify where data integration took a wrong turn for each session and what type of general information would have been beneficial at that point - such that a general pool of situation-specific cues may be designed and used for future navigation. What are the risks of such an approach? Clearly, if the cueing triggers a highly specific answer, the likelihood of AOL drive from this point on is considerable. For this reason, during the collection of S1-S2 data, the information elicited through these exercises should not be given any more consideration than every other piece of matrix data: ideally each should be recorded, then erased from the viewer's short-term memory and the target should be probed as if for the first time. Otherwise, trying to establish the general context too early in the process might unduly restrict or contaminate the data with preconceived notions. One's ability to temporarily disregard the results of these early contextual cues needs to be weighed against the ability to fight a premature scenario based on the aggregation of tangible S1-S2 information: both are a matter of psychology, rather than intrinsic process. But are there valid, process-based objections to this exercise? Is there a reason to believe that target aspects such as energy, function or emotions CAN NOT typically and reliably emerge so early in the process? This is perhaps an answer that can only be given by controlled experimentation and comparing the scores of standard sessions with those in which this cueing is used.
2. Creating artificial, abstract vocabularies
Proposal: To look into the possibility of creating an artificial ideogram/mental image vocabulary of highly abstract terms, with application to specific sciences/disciplines. This suggestion has to do with the abstract vocabulary we mentioned earlier in this article: for elements of the target that are recognizable, sensory mental images, the translation process is rather easy... But the more abstract the concept is - the more images it takes to construct the context, and the harder it becomes to identify the "right codon". Every time one re-sweeps the target, there is a good chance the perspective has changed, or one is no longer on the same aspect of the target. So the viewer ends up with a few dozen sensory and simple conceptual bits of data, begging the question: is there a novel, higher-level meaning that is supposed to emerge from all this, or is one supposed to take the data in a relatively literal sense? I think this becomes quite an important distinction in science applications, and anywhere else we have to balance known concepts against novel, unknown ones. Joe McMoneagle might have referred to the same problem when he talked about the difficulty of making predictions that are far into the future (The Ultimate Time Machine), given that we simply can't expect to understand technology which is so far advanced. But I think the same applies in everyday situations where a viewer is pitched against relatively unfamiliar concepts. Simple example: the viewer gets "grid; cross; cluster of points; snake-like curve". Most individuals seem conditioned to look for a pattern which fits this cluster of data on a tangible level - so they might come up with something like a group of people walking along a set of intersecting alleys at a zoo, watching a snake in a cage; however, to a mathematician trained to think primarily in abstract terms, the same cluster of data might immediately suggest the action of plotting a set of experimental results on a coordinate grid and tracing the best-fit function - while the actual shape of the "snake-like" curve might provide meaningful information about the type of function describing this situation. Since the level on which we tend to naturally integrate the data seems to be dependent on our own background, would it be possible to artificially design cues meant to identify the proper abstraction level required for a given target? And could we reduce the likelihood of "translation error" by artificially building a vocabulary of abstract concepts - to be trained into the mind as "single mental images", replacing the natural shortcut loops which form with extensive exposure to a particular field? We might be able to test the effectiveness of this exercise by training a group of viewers in such a vocabulary, then tasking both that group and a control group with the same set of specialized targets, and using separate, blind analysts to derive the meaning of the target. For the procedure to be successful, the first group would have to produce accurate, significantly higher-score reports about the precise conceptual meaning of the target.
_________________________ REFERENCES
Buchanan, Lyn (2003) The Seventh Sense. Paraview Pocket Books, New York, NY 2003 Stroud, Bill (2001) Making a Stray Cat Prolific: Thesaural Imaging and Remote Viewing. JNLRMI II(3) November 2003 Stroud, Bill (2001) The Essential Overlap Matrix: An Extension for a Remote Viewing Tool. JNLRMI II(3) November 2003 Pitkanen, M. (2003) Genes and Memes. JNLRMI II(3). November 2003 McMoneagle, Joseph (1998) The Ultimate Time Machine: A Remote Viewer's Perception of Time and Predictions for the New Millennium. Hampton Roads Publishing Co. Charlottesville, VA 1998
REPLIES/ COMMENTS
Comments
on "Data
Integration in RV: Abstraction Levels and Context"
I was very impressed with Lian's very excellent article and proposal for experimentation on a concept. This is the kind of thing we need more in this community. It can be found at: http://www.emergentmind.org/sidorovii3.htm I have a few comments, both pro and some which may at first sound con, but really aren't. The first thing I noticed was the basic tenet of the article.... that the viewer should seek to name or identify the target - at least the contextual basics of it. Second, he suggests that certain "neutral" cueing be used right after the viewer starts into Stage 2. Not having had CRV training, I don't think he realizes that such neutral cueing is a standard part of the CRV process. Therefore, on this one point, he has very effectively reinvented the wheel. A very necessary wheel, but he has come to this conclusion on his own - something for which I praise him very highly. He suggests, though, that the viewer
stop early in a session and ask him/herself these cues in the form of full-blown
questions and then analyze what little target contact has been established, in
order to get an answer The cues he suggests at this point are for gaining advanced, more conceptual information early on in Phase 2. This is one of the points of his article - that such information could be very helpful in this early stage, because it would let you make better sense of the raw sensories and dimensionals by being able to put them into a context. This brings us back to one of the most basic tenets of remote viewing.... you are not there to name or identify or even to understand. You are there to describe. You are the village idiot to whom the doctor, lawyer, and all the other town leaders come for advice. You don't have to understand it - you just have to be plain and honest and allow to spill out of your mouth whatever is going on in your mind. When you get down to it, the best remote viewers and the village idiot have many things in common. The reason for this basic
"describe, don't identify" tenet is that we, as humans, do our
thinking in very predictable and actually, very inefficient ways. One of our
first tendencies is to "pigeon-hole" or stereotype "For this reason, during the collection of S1-S2 data, the information elicited through these exercises should not be given any more consideration than every other piece of matrix data: ideally each should be recorded, then erased from the viewer's short-term memory and the target should be probed as if for the first time. Otherwise, trying to establish the general context too early in the process might unduly restrict or contaminate the data with preconceived notions. " In other words, he explains a second basic tenet of remote viewing, "There is no session above the line you're on." [I have to interrupt the point I'm
trying to make to add in one other comment of Lian's - which totally affects
everything.... Lian made the distinction throughout his paper between
inexperienced and experienced At the point of a viewer identifying
the target ("This is a monument in a park!"), the inexperienced viewer
will stop the session and want his/her feedback. Having seen that the target is,
indeed, a monument in a park, And this is key to the issue. If the
viewer is obligated to identify the target, then he/she can only "get"
those targets which are within his/her own experience. But, if the viewer's only
responsibility is to describe, But this gets back to Lian's statement
that, at some point in a session, the random perceptions will coalesce and the
viewer will suddenly realize what the target is. This happens automatically at
the advanced stages, As I read Lian's article, I understood
it to be an attempt to make this naturally-occurring coalescing happen on
demand, in the earlier stages. But this places an additional responsibility on
the viewer which, I am reminded of a time when I was in
northern Japan, where there are a lot of geysers. It is a mark of distinction
for a rock hound to have a personally procured "geyser stone". That
is, one of the stones which Anyway.... the point to all of that
totally senile digression.... when the inexperienced viewer is grabbing around
blindly in the darkness for anything which may or may not happen to bonk into
his/her mind, the lost But a more experienced viewer, simply
out of the natural course of gaining experience, will also gain the faith and
knowledge that the moment of target awareness will come in its own due time, and
be willing to work For the experienced viewer, the task during the early stages has become routine, and Lian's suggested method might be very helpful, even add some welcomed struggling to the now routine early stages of the experienced viewer's session. So, the reader of Lian's article should realize that this is a tool for more experienced viewers, and not for beginners.. Even the proposed experiment of creating advanced or complex contextual or conceptual ideograms is an experiment which is (or certainly should be) reserved for more advanced viewers. Viewers who haven't yet established a basic set of dependable ideograms should certainly not be given the task to create contextual ones. Further, Lian is aware of and raises the question mentioned above about identification requiring life experiences, when he asks: Since the level on which we tend to naturally integrate the data seems to be dependent on our own background, would it be possible to artificially design cues meant to identify the proper abstraction level required for a given target? And could we reduce the likelihood of "translation error" by artificially building a vocabulary of abstract concepts - to be trained into the mind as "single mental images", replacing the natural shortcut loops which form with extensive exposure to a particular field? His suggestion for the experiment is an
excellent one, scientifically based and scientifically valid. I hope that people
get involved in this experiment and I look forward to seeing the results. The
basic problems 1) a viewer will be trying to force what is otherwise a natural occurrence (this is not necessarily a bad thing, but might still be a problem.) 2) a viewer will be more prone to limit
the "best" sessions to those targets within his/her own personal
experienced. In fact, I would wonder whether or not doing this as a matter of
habit would retard a viewer's 3) since this is an advanced technique,
there will need to be a "qualification" process. The experiment, if
limited to more experienced viewers, would be valid. If inexperienced
viewers are included, simply Well, this is getting long... There are two bottom lines in all of this. Lian points out one of them when he says, But are there valid, process-based objections to this exercise? Is there a reason to believe that target aspects such as energy, function or emotions CAN NOT typically and reliably emerge so early in the process? This is perhaps an answer that can only be given by controlled experimentation and comparing the scores of standard sessions with those in which this cueing is used. So, the first bottom line is that, in
order to find out whether or not you can benefit from this idea, you have to try
it out, keep documentation, and make that documentation accurate. That is
the proposal made by this The other bottom line is that you need to become an experienced viewer, and that requires (cover your eyes, kids, I'm going to use the "P" word..) practice. Lots and lots of practice. I was very impressed by Lian's article
and his suggested experiment - and in fact, with the overall publication in
which it is located. I hadn't known about this source of remote viewing
information before, but
Lyn Buchanan, Problems Solutions
Innovations It's your mind - use it or lose
it.
RE:
"Data Integration in RV: Abstraction Levels and Context" RE: http://www.emergentmind.org/sidorovii3.htm Lian: Your paper (Remote Viewing Proposals: Data Integration in RV: Abstraction Levels and Context) addresses a question that, I think, has been relegated to a Neverland, but not one built by Michael; it is one left naturally standing from frustration with the usual limitations of the discipline of remote viewing. And your posing the question of a better integration of data is certainly timely and significant for current and future study of remote viewing dynamics. Unless I have misinterpreted Buchanan's take on this, he sets as the primary goal of CRV, not the identification of the target, but the acquisition of data about the target. This primary goal entails--again as I understand his position--a couple of corollaries as to methodology and progression dynamics; i.e., that the Structure was built to keep the focus at first on simple descriptors, tactiles, etc., and gradually progress to more complexity in S-4 and S-6. Imposing your desire for integration and more defined conceptuals at an early stage would seem to derail this sequential progression by addressing the problem up front, like trying to figure out where one is going on a trip by noting the first things seen out the window during the movement of a few blocks down the street. This, indeed, has a tendency to drive AOL's onto a fast horse headed for some sunset. As I understand CRV in the context of its tradition of concept development, its greatest value has been, not in target identification, but in the acquisition of descriptive data, data that can be used to amplify, clarify and supplement other sources of traditional informational gathering. I see the EOM as simply another step in discovering a common conceptual kernel among descriptors. If a detective finds a sea shell, a bit of sand, and a ball, he could conclude that the suspect had been to the beach. That type of work is strictly a deductive operation and strictly rational. However, with the EOM ("essential overlap matrix"), we are trying to ferret out condensations of themes, like trying to understand the grammar of the unconscious, not the plot of the story which the grammar is only related to as an underlying dynamic of symbol formation. I share your hope and frustration in trying to squeeze out of CRV a more focused target identification. Keep at it and let's try to move this wagon on down the road. Thanks for your effort and commitment to the discipline. Bill Stroud RE: Lyn Buchanan and Bill Stroud's comments on "Data Integration in
RV: Abstraction Levels and Context"
I am very grateful to Lyn and Bill for taking the time to read and reply to my suggestions: Lyn is one of the most experienced and most highly respected figures in the RV community, a true legend to some of us, and I have no doubt that his ability to anticipate the likely impact of these proposals is far more accurate than mine. I also think that Bill, as an advanced CRV student and a truly original thinker, is in a position to share valuable insights into these matters and steer our efforts in the right direction. This being said, I'd like to clarify a few points. Lyn is entirely right in stating that the worst thing a viewer could do is try to identify the target early in the session. The example he gives ("a monument in a park") is representative of such identification - but this is very far from what I had in mind. The challenge I presented was this: can we find a set of neutral, early cues that would lead to relevant abstract descriptors which are general enough that they, for all intents and purposes, CAN NOT coalesce into a preconceived meaning at this early stage? My suggestion was based on a precedent - the fact that our early ideograms and cues are in fact preliminary filters giving us basic information about the target: natural versus man-made structure, static versus dynamic, etc. We know that a triangle does not necessarily identify a mountain, and a square is not necessarily a box. We recognize the typical ideograms that our subconscious uses to represent living creatures, water, energy, etc - but we know better than to start putting together a scenario after the first three sketches. Indeed, we put all this information aside and forget about it until the first integration stage (S3 in the HRVG method) - at which point every element of the session is considered again against the full tapestry of data points, and the interpretation of ambiguous "terms" is decided in the context of our results. At that point, and that point only, do we apply logical deductions for any significant length of time. And it is also at that point that we may be allowed to ask ourselves: do we assign slightly more credibility, or weight, to the early data - is there a chance that the essential (to the tasker) features of the target were less contaminated in the early contact by our inherent attraction to more "exciting", if tangential, aspects? (The rationale could be that the preliminary "contact" with the target is made through the aligned intent of viewer and tasker, while later in the session the viewer is more free to move around the already "familiar" target.) If early functional cues can help us circumscribe the aspects of greatest interest to the tasker, then the advanced protocols can be used more effectively. The alternative is, of course, using a monitor to steer the viewer toward those aspects that are more critical to the investigation - but as everyone knows, monitoring is never 100% free of unwanted influences. My aim was thus simply to expand the classes of early descriptors to include more functional reference points - such as the predominant form of energy and motion, the relative prominence of physical versus emotional or intellectual activity, the perceived "urgency" of the situation, etc... As I said earlier, these were mere examples - it would be up to the RV community to pool its collective experience and decide what types of cues would best fulfill the above criteria. Once the ideal cues have been identified, they should be condensed to 1-2 word prompts, rather than elaborate questions (which are indeed distractive). The other idea that Lyn addressed was my proposal to develop a higher-level vocabulary of unique mental images/ideograms to help us navigate more abstract targets. I think his concerns are very insightful and valid: ********************************************************************************* [...] suggestion for the experiment is an excellent one, scientifically based and scientifically valid. I hope that people get involved in this experiment and I look forward to seeing the results. The basic problems will still be there, however, that: 1) a viewer will be trying to force what is otherwise a natural occurrence (this is not necessarily a bad thing, but might still be a problem.) 2) a viewer will be more prone to limit the "best" sessions to those targets within his/her own personal experienced. In fact, I would wonder whether or not doing this as a matter of habit would retard a viewer's ability to get targets which are not within his/her personal experience. 3) since this is an advanced technique, there will need to be a "qualification" process. The experiment, if limited to more experienced viewers, would be valid. If inexperienced viewers are included, simply because they want to be a part of a research project, or because they overestimate their abilities, the real potential for the process to do harm to those viewers' learning curve is real. *********************************************************************************** I think the primary concern here should be the potential for "over-specialization" in a particular field. Someone who spends an extensive amount of time developing physics or mathematics-related ideograms will likely end up "seeing" such ideograms in almost every target he/she is assigned. But that has always been a caveat in RV: people who are primarily tasked with missing persons cases will develop a strong expectation that the next target will be of the same nature. Viewers who are obsessed with UFOs or conspiracy theories will develop this type of story line in a remarkable proportion of their sessions. Nothing new so far - we simply need to make sure that our targets cycle through a healthy spectrum of subjects and suspend all expectations. I would certainly not recommend that a viewer try to become an "expert" in a particular field by developing an advanced vocabulary of concepts limited to that discipline: I fully agree with Lyn that such an attempt would be disastruous both to the long-range quality of the viewer's sessions, and to viewer himself. But I believe that the development of a well balanced thesaurus of abstract ideograms (including concepts from fields such as physics, biology, politics, sociology, geology, religion, etc) can lead to a gradual increase in the specificity with which we are able to probe our targets. RV in its present form is designed primarily for describing the tangible world around us. If we limit ourselves to that vocabulary, it's unlikely that we'll be able to get far in our scientific projects: it's really not all that different from our normal use of language - we would not expect a first grader to understand the theorems of trigonometry or calculus, although they know circles and curves: those packages of reinforced knowledge which are later evoked by the simple mention of a specialized term are not available for easy manipulation in their minds. Joe McMoneagle once spoke about how the Stargate viewers were tested on a series of targets representing various mechanical implements, in order to see how well they could differentiate between different technologies. That is what I'm talking about: getting correct glimpses of the target is far easier than being able to integrate that information at the next level of abstraction - which is, for example, "process". It is not a specialized vocabulary of target "identities" I am arguing for, but one of higher-level classes, such as purpose or dynamics, which our minds are not currently trained to explore and communicate effectively. As far as forcing a process to occur prematurely, I would not include these highly abstract concepts among the early cues discussed above: I would expect that, with sufficient repetition, they will arise spontaneously at various points in the session, and simply add to the overall pool of data. Finally, at no time should the viewer attempt to force a choice between available categories: all such lists of higher descriptors should be considered OPEN, allowing for the possibility that the purpose, process or any other aspect one is aiming to describe is one which may not be part of our current conceptual vocabulary. If anyone is interested in pursuing some of these exercises, a list of abstract descriptors and categories has been started already: we look forward to your additional comments and suggestions. Sincerely, Lian
|
|
Copyright � 2000-2006 EmergentMind.org
|